Behavioral Analysis of Vision-and-Language Navigation Agents
To be successful, Vision-and-Language Navigation (VLN) agents must be able to ground instructions to actions based on their surroundings. In this work, we develop a methodology to study agent behavior on a skill-specific basis – examining how well existing agents ground instructions about stopping, turning, and moving towards specified objects or rooms. Our approach is based on generating skill-specific interventions and measuring changes in agent predictions. We present a detailed case study analyzing the behavior of a recent agent and then compare multiple agents in terms of skill-specific competency scores. This analysis suggests that biases from training have lasting effects on agent behavior and that existing models are able to ground simple referring expressions. Our comparisons between models show that skill-specific scores correlate with improvements in overall VLN task performance.
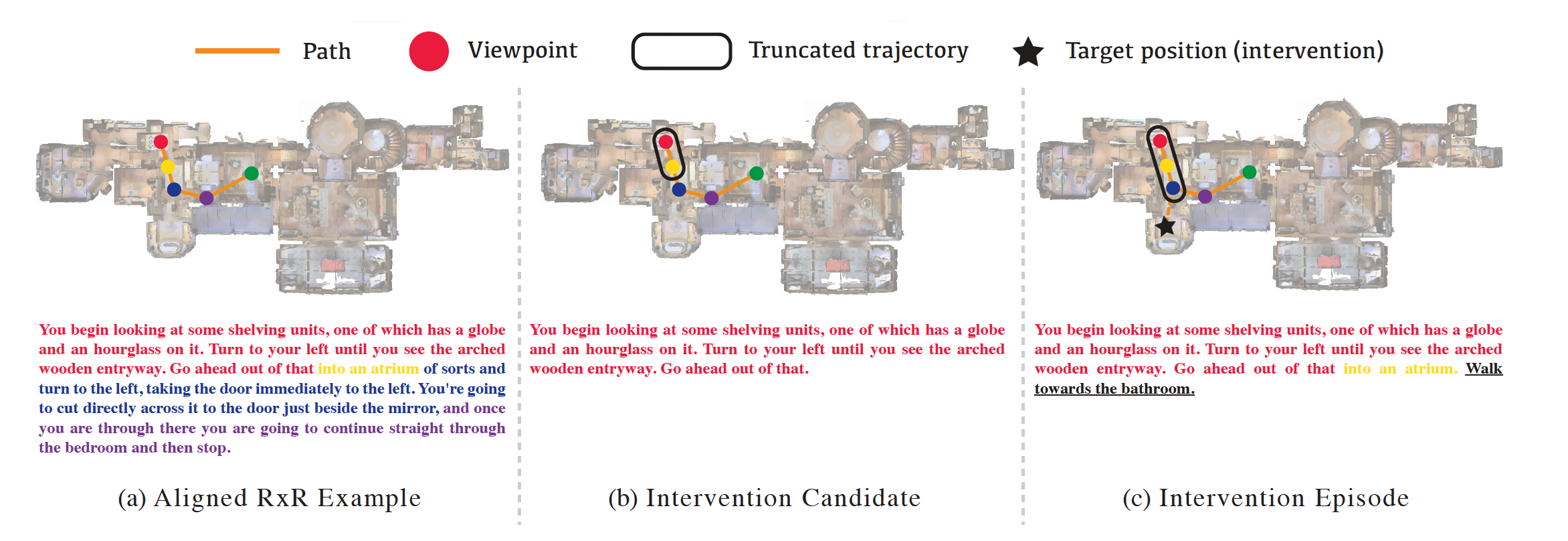
We consider an intervention sample to be a tuple consisting of a trajectory \(\tau\) , an instruction $I$ that guides an agent to the end of that trajectory, and an intervention instruction $I_{int}$ that describes some desired skill-specific behavior to be taken from that point. For intervened episodes, an agent will be given the augmented instruction $I+I_{int}$, guided through the trajectory $\tau$ and then its decision will be compared to the expected behavior described in $I_{int}$. We choose this partial-path construction so we can vary pre-intervention path length while keeping trajectory-instruction alignment similar to standard VLN training settings. Figure 1 (c) shows one such triplet with a 3-step trajectory, an instruction describing it, and an underlined intervention prompting the agent to move “towards the bathroom”. We design different interventions to study fine-grained skills: Stop, Turn, Object-seeking, and Room-seeking.
Stop
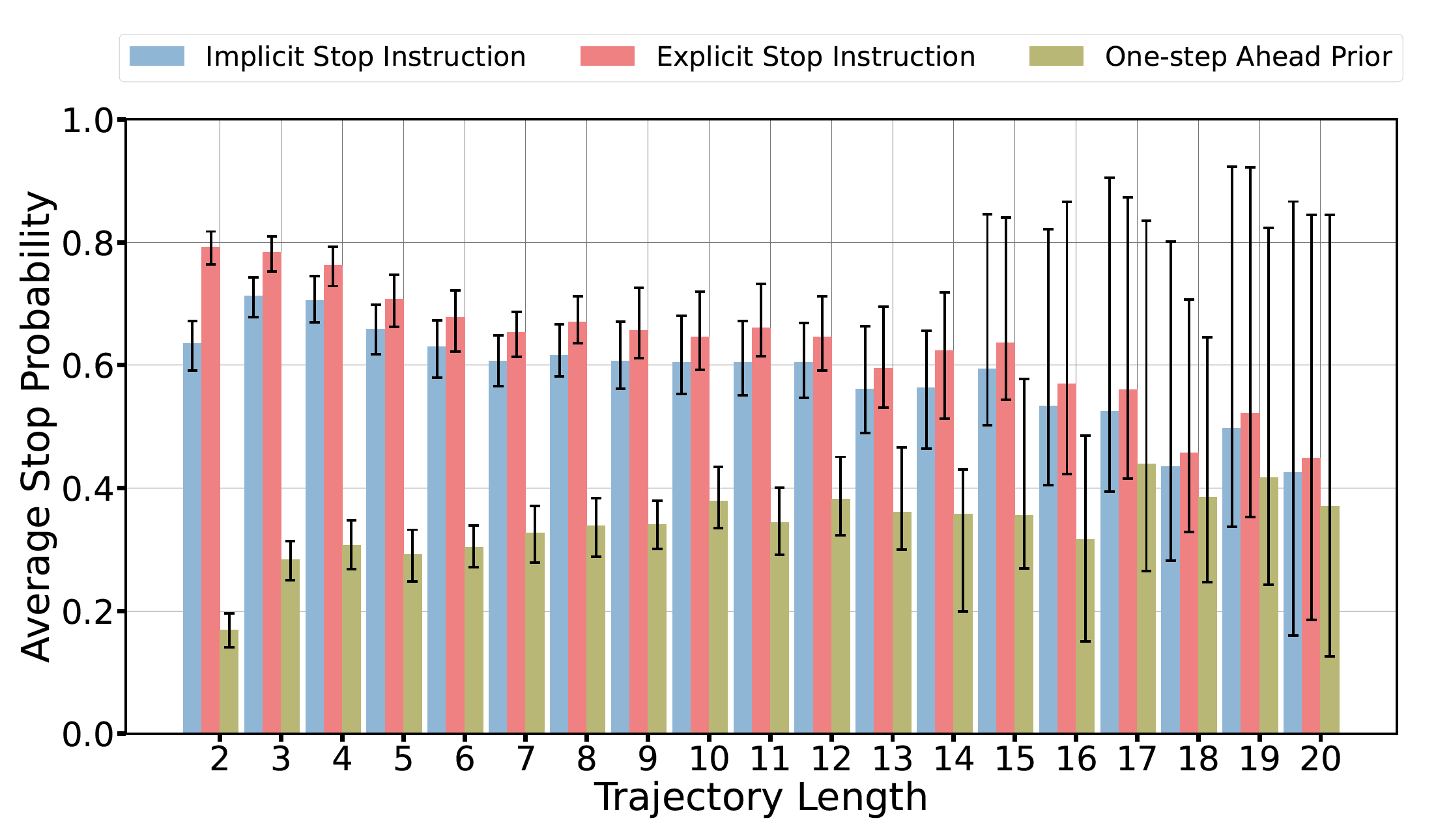
To be successful at the VLN task, an agent must declare the stop action within a fixed radius of the goal location described by an instruction. As such, grounding explicit (Go to the bedroom and stop. ) and implicit (... then go into the bedroom.EOS) stopping instructions to the stop action is an important skill. In this experiment, we analyze stop behavior for explicit or implicit stop instructions. To assess the effect of path length distributions in RxR, we examine stop behavior across a range of path lengths. For intervention instructions, we append a short stop
instruction such as “This is your destination.” We note
however that the stop experiment offers a complication –
both the truncated and intervened instructions imply stop
actions. The difference being whether this instruction is
implicit (truncation) or explicit (intervention). To provide
additional comparison with non-stop instructions, we also
consider a one-step ahead instruction that includes the in-
struction segment from the terminal node as well (i.e. the
agent is instructed to make the next step in the trajectory).
We find average stop probability to remain fairly constant for implicit and explicit stop instructions.(Note that longer trajectories have fewer episodes and larger variation.) This suggests agents consistently ground the stop instruction regardless of trajectory length despite biased RxR training trajectory length (Figure 2).
We also find stop probability is higher for explicit than implicit stop which are both naturally higher than the one-step ahead setting with 95% confidence. (Check paper for details)
Direction
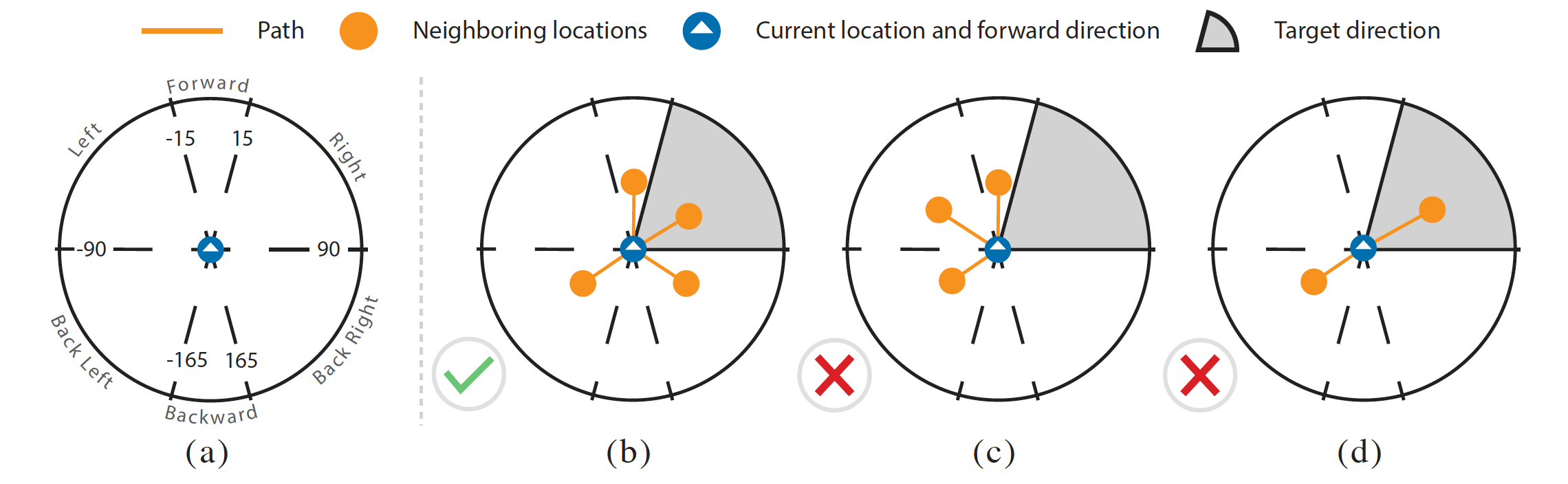
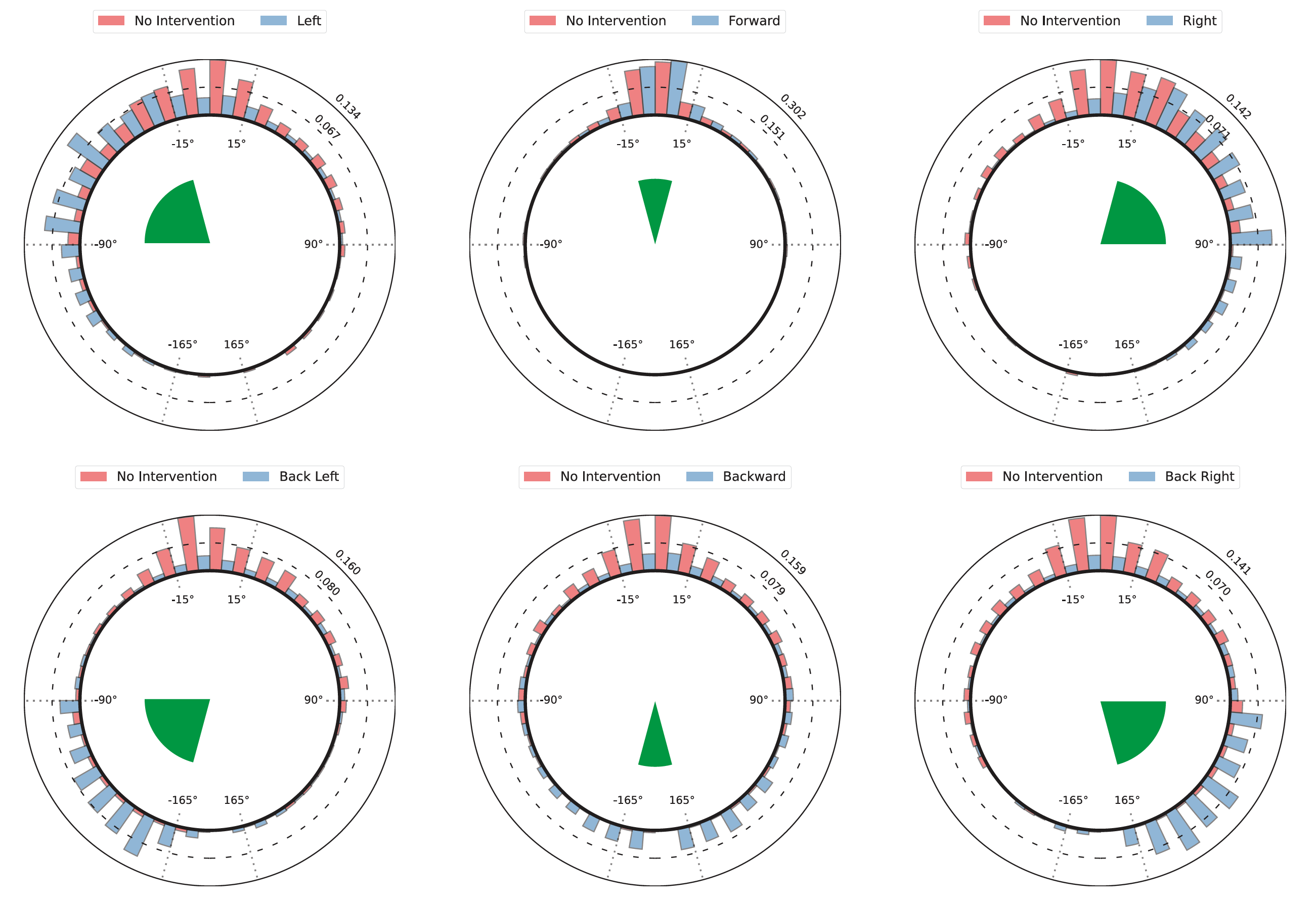
Another foundational skill for following navigation instructions is responding appropriately to directional language. In this experiment, we examine unconditional directional instructions which specify directions like turn left and go forward without referencing entities in the environment. We consider language describing forward/backward motions and turns. Specifically, we explore six direction categories -- forward, backward, left, right, back left, and back right. For each, we define an angular region relative to the agent's heading (canonically 0 degrees) as shown in the top-left of Figure 3. During our experiment, we can examine the amount of probability placed on neighboring nodes within these regions. These can be mapped to beliefs over relative angles by associating the probability of visiting neighbor k with the relative angle $θ_k$ between the agent’s heading and neighbor k. Figure 4 shows the distribution of these probabilities over all episodes for each intervention as histograms on polar axes. We find the agent exhibits a significantly higher accumulated probability for the corresponding direction with directional instruction than without with 95% confidence. (Check paper for details)
Object-seeking
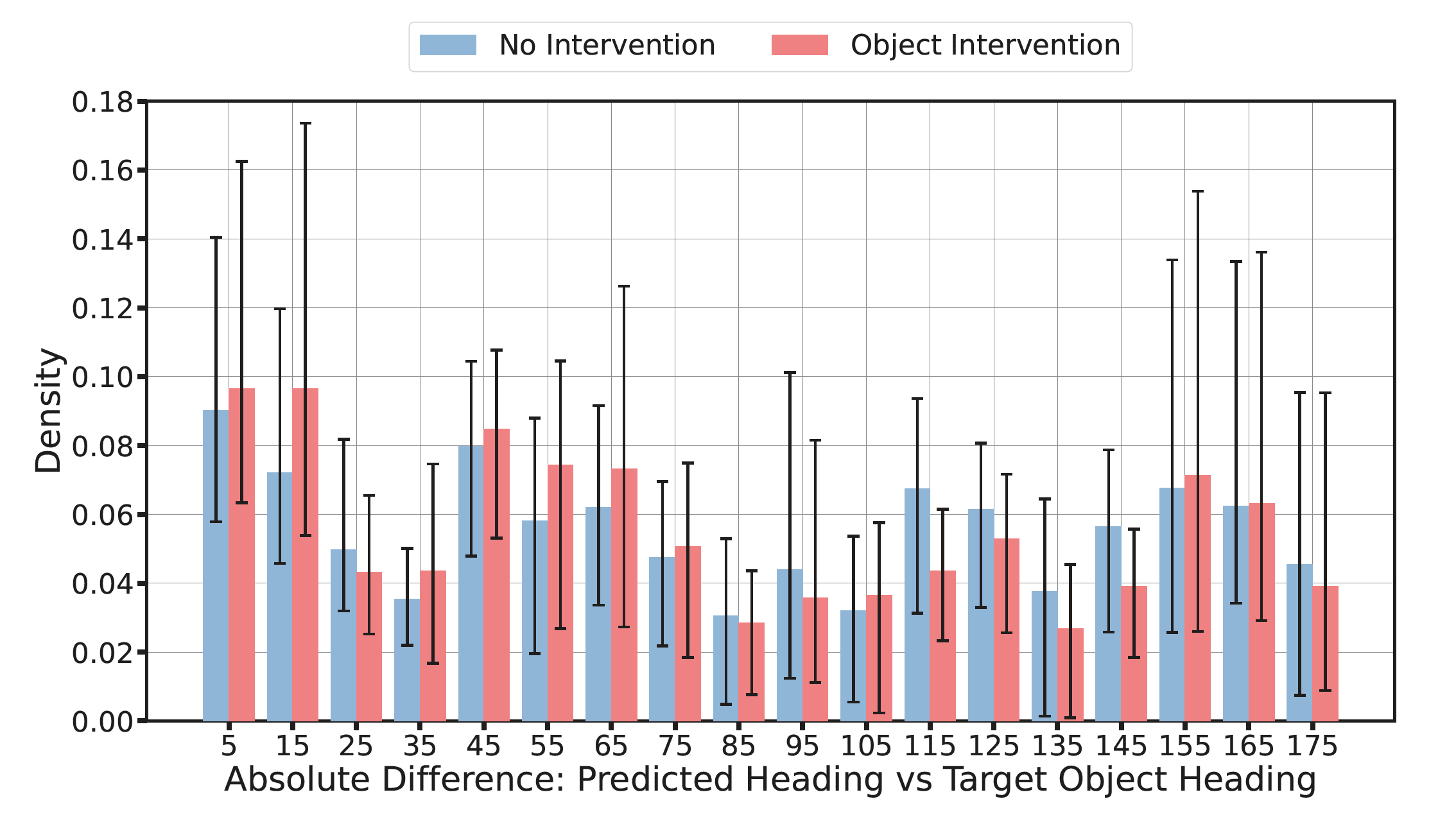
Beyond directional language, instructions also often use references to nearby objects as convenient landmarks, e.g. Walk towards the fireplace . Unlike the language studied in the previous sections, object-seeking instructions require grounding the instruction to the visual scene. We examine simple "walk towards X" style object-seeking instructions.
Using the REVERIE dataset's object annotations, we create intervention episodes for visible objects that are within 3m distance and have a neighboring node with a heading within 15 degrees. Common objects like doors, windows, and railings are excluded. We generate 839 intervention episodes with the instruction to "Walk towards the object." Objects targeted in descending order of occurrence are chair, table, picture, cushion, curtain, plant, cabinet, gym equipment, stool, chest of drawers, bed, towel, bathtub, TV monitor, and seating. We record the agent's predicted distribution over neighboring nodes for each episode and map them to a distribution over angular errors relative to the object. We compute the difference in heading angle between each neighbor and the object, and associate the probability of visiting each neighbor with an angular distance to the target object. These probabilities are accumulated and normalized to produce a distribution over angular distance for the intervention and no-intervention settings. The intervention has a weak effect on reducing angular error. A linear mixed effect model finds a weak fixed effect of 0.069 for intervention vs non-intervention. Both settings exhibit a wide range of angular errors. A baseline Forward Bias agent shows a similar error distribution. The no intervention setting is more likely to stop than the intervention. We find evidence for only a weak tendency to move towards referenced objects for this agent.
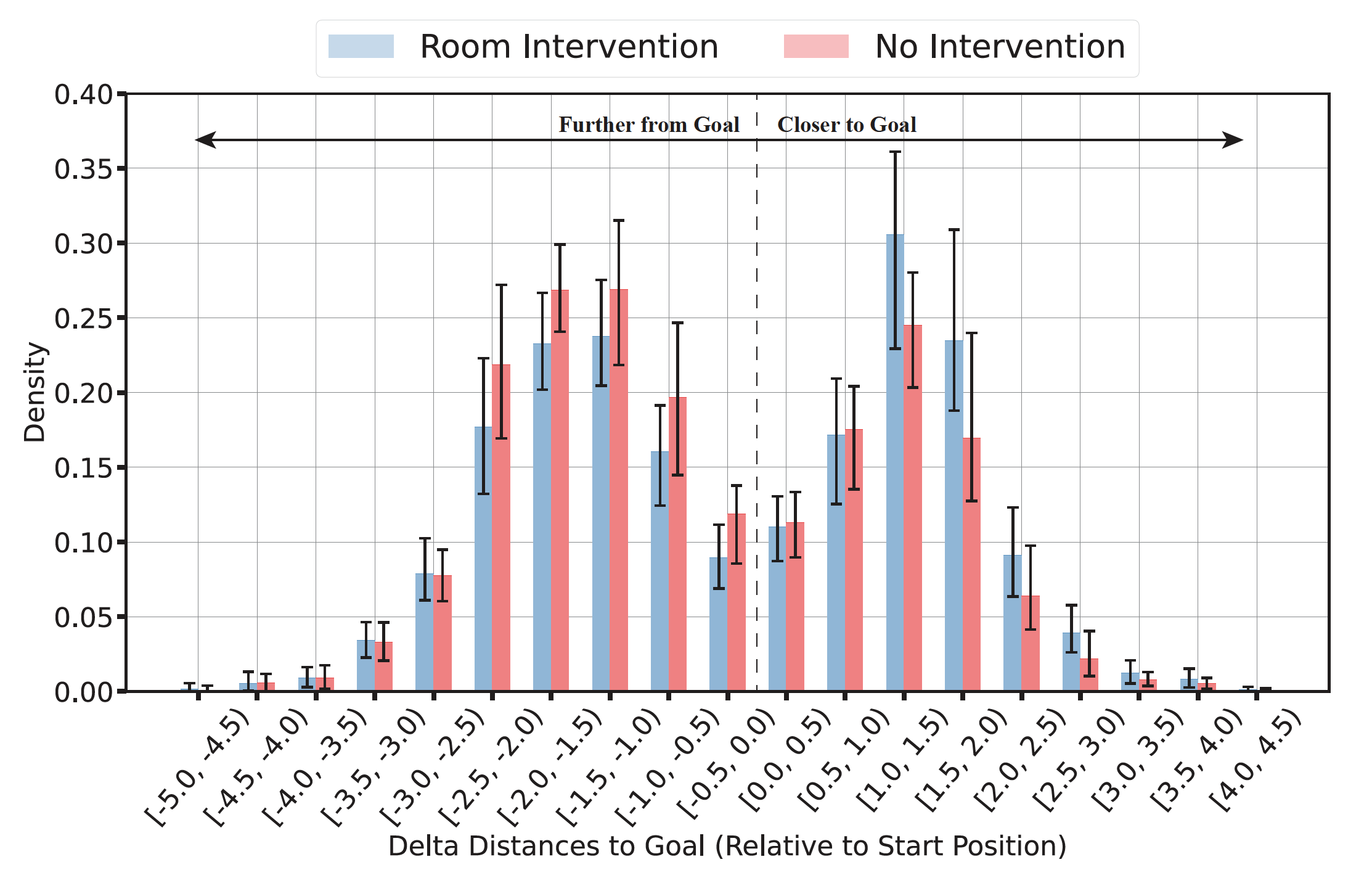
Room-seeking
In the experiment, agents are given room-seeking instructions to navigate to specific rooms, with 1-hop settings representing visible rooms (Figure 6) and k-hop settings representing rooms that may require searching. Using Matterport3D room region annotations, intervention candidates were created for 1-hop and k-hop settings. For 1-hop results, agents' progress towards target rooms was measured using a distribution over change in geodesic distances to the nearest node with the target room type. The right-shift in the density suggests that agents respond somewhat to the intervention. The effect of intervention on delta geodesic distance was significant, but agents didn't reliably place strong beliefs on neighbors with the target room type. (For n hop results, check paper)
Skill Sensitivity Comparision
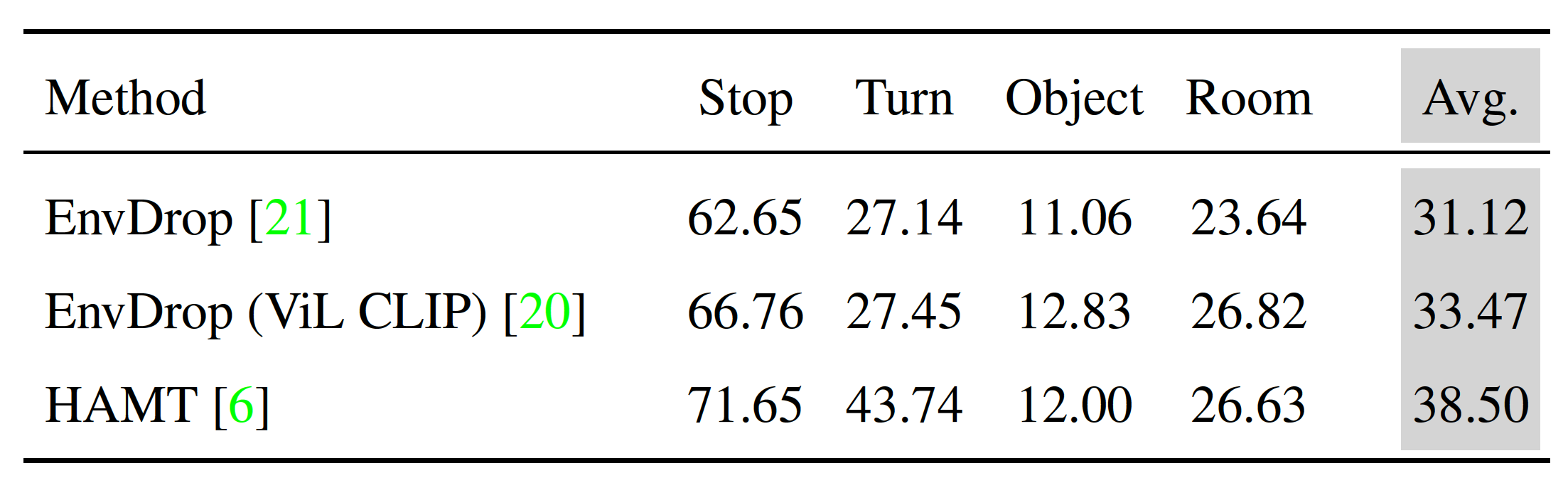
In skill-specific interventions, we identify correct actions for various instructions like stopping, turning, object-seeking, and room-seeking. To compare Vision-and-Language Navigation (VLN) models, we calculate the average probability mass placed on these correct actions using a scoring function. This function takes into account the intervention episodes, agent's predicted probability for action, and other factors. Higher scores indicate better certainty in selecting grounded actions. When comparing three VLN agents with varying performance, (Figure 7.) we observe that improved overall task performance also leads to improvements in skill-specific scores. However, these improvements aren't uniform across skills, and agents are more proficient at handling stopping and turning instructions than those related to objects or rooms.
Email — yangziji@oregonstate.edu